
KI macht täglich Schlagzeilen: neue Modelle, beispiellose Partnerschaften, innovative Produkte. Während ChatGPT sein dreijähriges Jubiläum feiert, ist die Landschaft der künstlichen Intelligenz zu einem Labyrinth geworden, in dem dieselben Akteure auf mehreren Fronten gleichzeitig konkurrieren. Alphabet tritt gegen Nvidia auf dem Chipmarkt an, während Gemini mit ChatGPT als Sprachmodell rivalisiert. Aber wie verbinden sich diese verschiedenen Schlachten, und was ist der rote Faden hinter diesem technologischen Krieg?
Erklärung der CPU-, GPU- und TPU-Prozessoren
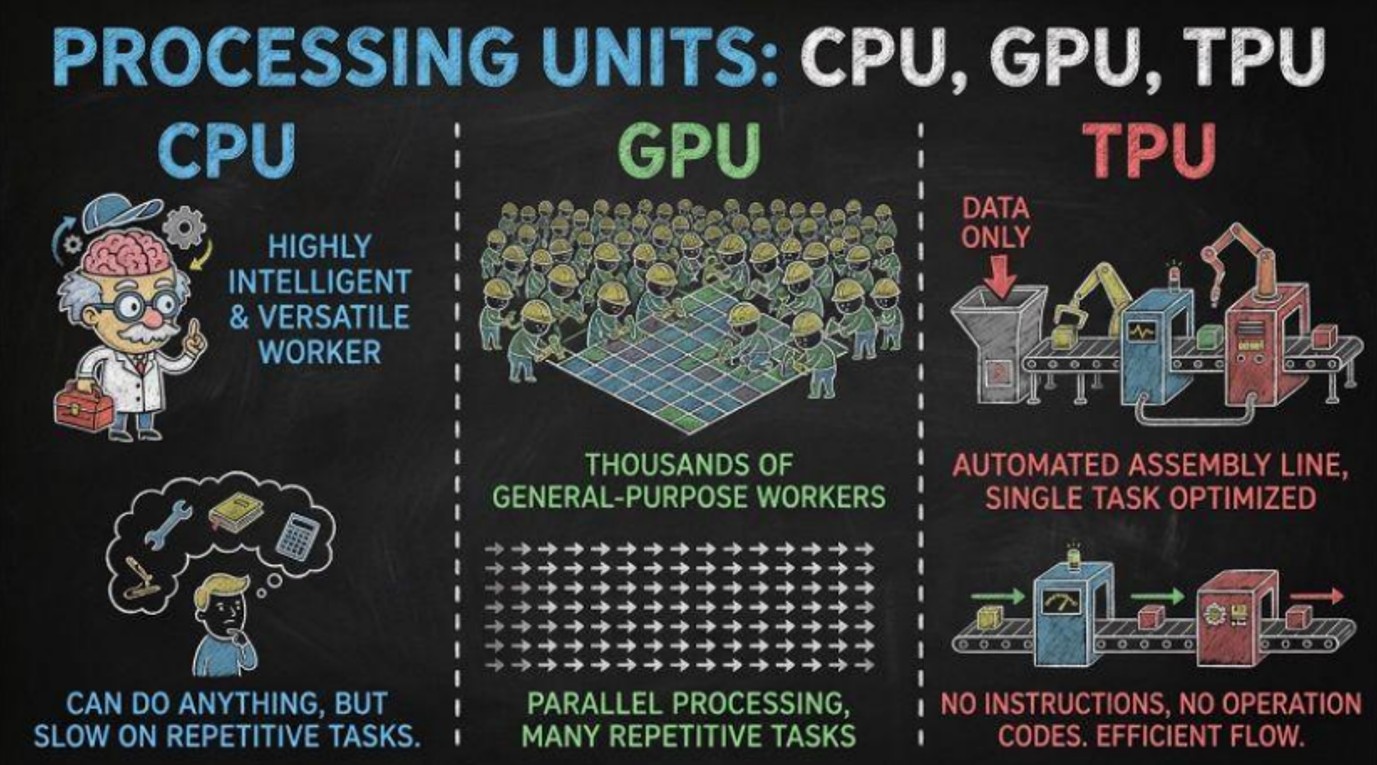
CPU bilden das Herzstück der Computer seit den Anfängen der modernen Informatik. Noch heute arbeitet jeder Computer mit einem CPU. Es ist der Hauptprozessor und fungiert als das Allzweck-Gehirn des Computers. Ohne ihn könnte Ihr Computer nicht einmal starten. Allerdings wurden diese Chips für Flexibilität konzipiert und nicht für wiederholte Berechnungen. So, in den 1990er Jahren, als Videospiele immer realistischer wurden, benötigten Computer Chips, die Millionen von Pixeln gleichzeitig verarbeiten konnten, statt nur einen Pixel nach dem anderen. Das führte zu Graphics Processing Units (GPUs). Eine GPU besteht im Wesentlichen aus Tausenden von einfachen Recheneinheiten, die parallel arbeiten. Während ein CPU Pixel nacheinander färbt, färbt eine GPU alle gleichzeitig. Die meisten Computer heute besitzen sowohl eine CPU als auch eine GPU. Und der größte GPU-Hersteller war Nvidia.
Dann kam die moderne KI. Das Training großer neuronaler Netzwerke erfordert enorme Mengen an Matrizenberechnungen, und diese Berechnungen ähneln fast genau dem, wofür GPUs bereits für 3D-Grafiken ausgelegt waren. Nvidia hat dies genutzt, indem es GPUs für Rechenzentren geeignet machte, die viel größer und leistungsfähiger sind als die Laptops, und gewann schnell einen enormen Marktanteil. GPUs blieben jedoch weiterhin vielseitige Grafikchips, keine speziell für KI entwickelte Chips. Im Jahr 2015 führte Google die Tensor Processing Unit (TPU) ein, die speziell für Operationen konzipiert wurde, die in neuronalen Netzwerken verwendet werden. Mit anderen Worten, der TPU ist ein ASIC (Application-Specific Integrated Circuit), ein maßgeschneiderter Chip für eine bestimmte Verwendung, statt für allgemeine Zwecke. Diese Spezialisierung ermöglichte es den TPU, ein besseres Kosten-Nutzen-Verhältnis, eine höhere Energieeffizienz und eine hohe Durchsatzleistung in großem Maßstab zu bieten.
Schließlich gibt es noch eine andere Chip-Art, die neuronale Verarbeitungs-Einheit (NPU). Sie arbeitet direkt auf dem Gerät (zum Beispiel Smartphones) und konzentriert sich auf Energieeffizienz und die Echtzeit-Verarbeitung von KI. Sie konkurriert nicht mit GPUs und TPUs, da sie weit davon entfernt ist, ideal für das Training großer KI-Modelle zu sein, und über eine geringere Rechenleistung verfügt. Da sie jedoch für Anwendungen mit geringem Energieverbrauch optimiert ist, wird sie überwiegend in Anwendungen wie Bildverarbeitung und Spracherkennung in Echtzeit eingesetzt.
Quelle: Leon Zhu & SemiVision auf X
Aber wenn TPU besser sind als GPU für Training und Inferenz, warum verwenden dann nicht alle LLMs TPU?
Denn die Geschichte hat die KI-Welt lange vor der Einführung der TPU in GPUs eingeschlossen. So sehen die Dinge aus: Zu der Zeit, als Google 2015 die TPU erfand, hatte die Welt des maschinellen Lernens bereits ein Jahrzehnt damit verbracht, alles aufzubauen – von Suchcode, ersten neuronalen Netzbibliotheken, Universitätskursen bis zur Unternehmensinfrastruktur – basierend auf Nvidia-GPUs. Und der Grund war nicht nur, dass „GPUs gut sind“. Es war CUDA, die proprietäre Programmierplattform von Nvidia, eingeführt 2007.
CUDA ermöglichte es Entwicklern, Code zu schreiben, der direkt die parallele Leistungsfähigkeit von GPUs nutzte. Es war stabil, schnell, gut dokumentiert und vor allem funktionierte es überall – von Gaming-PCs bis zu riesigen Rechenzentren. Das erzeugte eine Momentum-Effekt. Je mehr Entwickler CUDA nutzten, desto mehr Tools und Bibliotheken wurden für CUDA erstellt, was mehr Unternehmen dazu brachte, Nvidia-GPUs zu kaufen, und schließlich noch mehr Entwickler zu CUDA zu treiben.
Zu Beginn der 2010er Jahre war das Ökosystem darauf aufgebaut, dass Leute Nvidia-GPUs und CUDA verwendeten. Universitäten lehrten es. Startups setzten es um. Cloud-Anbieter füllten ihre Rechenzentren damit.
Als Google die TPU einführte, waren sie zwar leistungsstark, besonders für das Training und die Inferenz im großen Maßstab, doch sie waren auch deutlich unflexibler als GPUs in Bezug auf Modelltypen und Operationen, die sie verarbeiten konnten. Und noch wichtiger: Sie kamen zu spät zu einer Party, die Nvidia seit Jahren ausrichtete, und die gesamte Community hatte ihr Haus bereits auf CUDA aufgebaut.
Außerdem vertreibt Google keine TPU. Wenn man sie nutzen wollte, musste man sein Modell auf Google Cloud trainieren. In der Zwischenzeit waren Nvidia-GPUs überall: Amazon, Microsoft, Oracle, private Rechenzentren, Universitätscluster. Diese breite Verfügbarkeit machte GPUs zum Standardwahl für jeden, der ein LLM baute.
Aber dennoch führten die besseren Leistungen der TPU und der Wunsch, sich weniger auf ein einziges Unternehmen (in diesem Fall Nvidia) zu verlassen, dazu, dass Akteure begannen, Googles Chips in ihre Wertschöpfungskette zu integrieren. Anthropic hat kürzlich eine mehrjährige Milliardenzusage mit Google abgeschlossen und Zugriff auf bis zu eine Million TPU erhalten. Ihre Modelle werden künftig auf drei Plattformen laufen: den Nvidia-GPUs, den von Amazon maßgeschneiderten Trainium-Chips (ebenfalls ASICs) und den Google-TPUs. Meta soll ebenfalls mit Alphabet in Verhandlungen stehen, um bis 2027 Milliarden in Googles TPU-Chips für seine Rechenzentren zu investieren. Das würde dem Unternehmen helfen, seine Chip-Beschaffung über Nvidia- und AMD-GPUs hinaus zu diversifizieren. Allgemein suchen immer mehr Unternehmen danach, eigene ASICs zu bauen. Zum Beispiel hat OpenAI eine neue Vereinbarung mit Broadcom getroffen (die beim Aufbau der Google-TPU geholfen hat), um ab 2026 eigene ASICs zu entwickeln.
Zwei Lager in der KI
Der Kampf um die Vorherrschaft in der künstlichen Intelligenz scheint sich heute in zwei konkurrierende Blöcke gespalten zu haben. Auf der einen Seite das „Google-Kartell“, das um Alphabet und ein umfassendes Netzwerk von Infrastrukturanbietern (Broadcom, Celestica, Lumentum, TTM Technologies) zentriert ist. Auf der anderen Seite das „OpenAI-Kartell“, fokussiert auf OpenAI und unterstützt von Partnern wie Microsoft, Nvidia, Oracle, SoftBank, AMD und CoreWeave. Microsoft sorgt sowohl finanziell als auch mit der Cloud-Infrastruktur Azure dafür, dass OpenAI seine Modelle trainiert und deployed. Nvidia und AMD liefern die GPUs und Beschleuniger, die für diese Rechenleistung unabdingbar sind. CoreWeave, teilweise im Besitz von Nvidia, fungiert als spezialisierter Hochleistungs-Cloud-Anbieter und stellt riesige GPU-Cluster bereit, um einen Teil der Trainingsarbeit zu absorbieren, die Azure nicht allein bewältigen kann. Oracle wiederum hat mehrjährige Vereinbarungen getroffen, OpenAI-Laufwerke auf der eigenen Cloud zu hosten, wodurch der Rechen-Öko erweitert wird.
Pendant près de deux ans, toute proximité avec le «Complexe OpenAI» a été saluée par les marchés. Un nouveau contrat d’approvisionnement en puces avec Nvidia, une extension des capacités cloud chez Oracle ou encore un simple rapprochement stratégique avec OpenAI suffisait à déclencher des hausses marquées, tant les investisseurs anticipaient une croissance fulgurante de la demande en IA et des revenus associés.
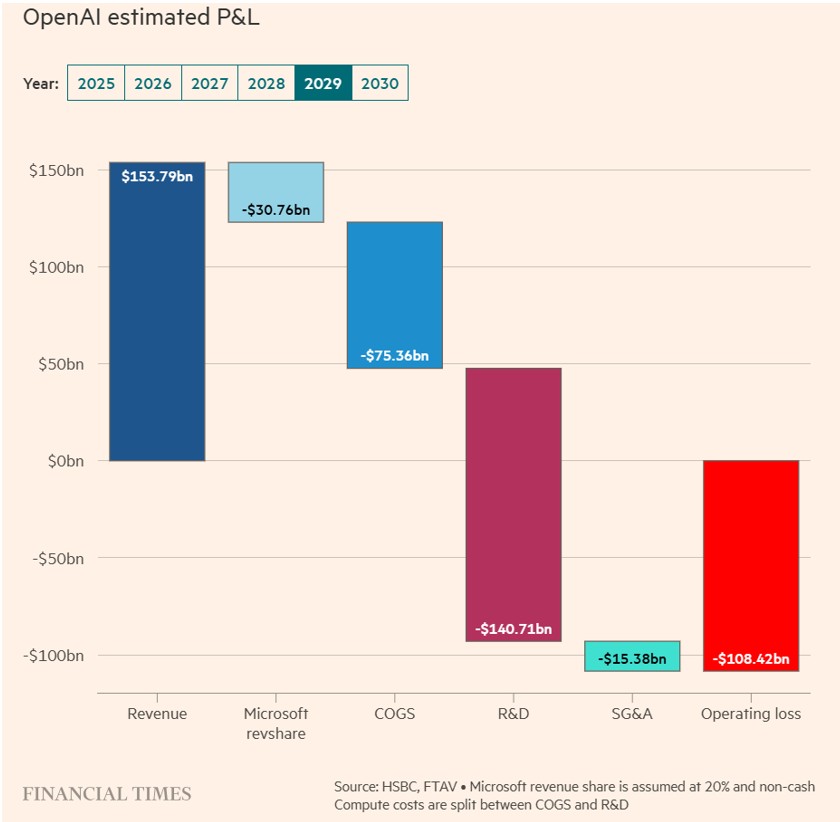
Cette dynamique s’est cependant inversée ces dernières semaines. Désormais, un lien étroit avec OpenAI est perçu comme un risque plutôt qu’un atout. SoftBank, qui détient environ 11 % du capital d’OpenAI, a chuté de près de 40 % en novembre. L’action Oracle, qui s’était envolée après l’annonce d’un accord d’infrastructure colossal à 300 milliards de dollars, voit désormais ses credit-default swaps s’écarter sensiblement, les investisseurs réévaluant le risque de construire des capacités massives pour un client dont la solidité financière apparaît nettement plus fragile qu’escompté. Même Microsoft, pourtant protégé par sa taille et sa diversification, n’a pas échappé aux pressions. HSBC estime désormais qu’OpenAI pourrait cumuler près de cinq-cents milliards de dollars de pertes opérationnelles d’ici 2030, une estimation qui soulève de sérieux doutes quant à la viabilité financière d’un écosystème déjà alourdi par des investissements colossaux, un recours accru à l’endettement et des valorisations élevées.
Quelle: Financial Times
À l’opposé, le Google Complex repose sur une discipline d’investissement remarquable, une infrastructure interne colossale et des marges solides. Sur la dernière année, Alphabet a généré 151,4 milliards de dollars de flux de trésorerie opérationnels, de quoi financer près de 78 milliards de dollars de dépenses d’investissement, rembourser environ 20 milliards de dollars de dette et distribuer près de 70 milliards de dollars aux actionnaires sous forme de rachats d’actions et de dividendes. Rares sont les entreprises engagées dans la course à l’IA capables d’atteindre un tel niveau de génération de trésorerie, combinant un free cash-flow robuste et une pression de bilan limitée, surtout comparées au «Complexe OpenAI». Cette solidité permet à Alphabet de déployer sans difficulté des modèles comme Gemini 3. En entraînant ce dernier exclusivement sur ses propres TPU, Alphabet réduit drastiquement ses coûts internes de calcul tout en posant les bases d’une activité Hardware stratégique.
Cette puissance financière et cette intégration verticale se reflètent désormais dans les performances du modèle. Gemini 3 s’est hissé au sommet des classements internationaux et est aujourd’hui considéré comme le modèle le plus avancé du marché. Dans le dernier classement LMArena, il arrive largement en tête des votes. Marc Benioff, CEO de Salesforce, n’a pas caché sa réaction après l’avoir testé: «J’ai utilisé ChatGPT tous les jours pendant trois ans. Deux heures avec Gemini 3, je ne reviendrai pas en arrière.»
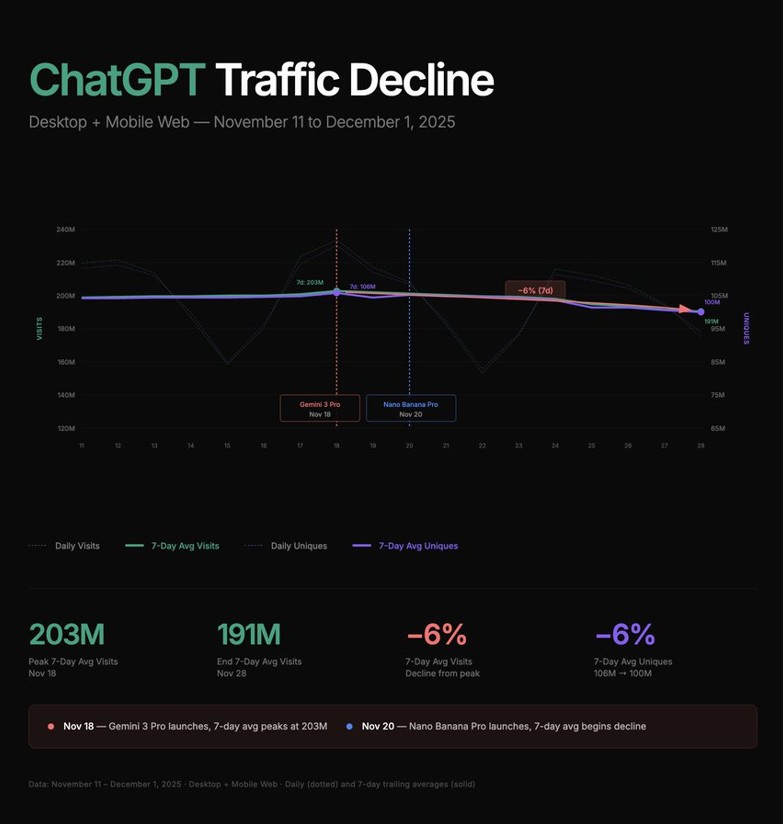
Ce choc de performance a exercé une pression tangible sur le «Complexe OpenAI». Sam Altman aurait diffusé une note interne de «code rouge» après le lancement de Gemini 3, reconnaissant la menace croissante posée non seulement par Google, mais aussi par Claude d’Anthropic. Les données SimilarWeb montrent que le trafic de ChatGPT a chuté d’environ 6 % dans les semaines suivant l’arrivée de Gemini 3, passant de 203 millions à 191 millions de visites quotidiennes.
Quelle: Deedy Das auf X
Schlussfolgerung
Nvidia bleibt eine unaufhaltsame Kraft, und die Nachfrage nach seinen GPUs bleibt extrem hoch. Die neuen Architekturen Blackwell und Rubin könnten seine Position bereits ab 2026 weiter festigen. Allerdings entwickeln die großen Cloud-Anbieter jetzt eigene Chips, die Margen ziehen sich zusammen, und Investoren zeigen sich zunehmend vorsichtig gegenüber dem finanziellen Hebel und der Überinvestition, die das OpenAI-Ökosystem umgeben. Der wahre defensivste Trumpf von Nvidia bleibt sein CUDA-Software-Ökosystem und seine Vorherrschaft bei den Trainingslasten der Modelle.
Es handelt sich nicht um ein Nullsummenspiel. Der KI-Markt wächst zu schnell, als dass es nur einen Gewinner geben könnte. Zwei Zentren der Gravität entstehen heute: Alphabet, mit seinem integrierten, hocheffizienten Stack, getragen von einem Gemini, der sich im Aufstieg befindet; und Nvidia, unterstützt von einem unvergleichlichen Software-Ökosystem und einer klaren Führungsrolle im Training.